IN THIS ARTICLE
Scene Graph
SceneGraph 是一个双向 a 循环图,以少量命名条目(最多 200 万)为目标。它通过传统的索引检索或自定义迭代器,支持对存储数据进行分层和平面迭代。树状图中的节点可以通过对所有条目合成的类似路径的名称快速定位。
场景 管道特别使用SceneGraph,因为导入的文件(如 FBX 文件)会根据它们之间的关系添加大量有关其内容(如网格、材质、变换、动画等)的附加信息。这些内容通常具有对艺术家有意义的相关名称。例如,艺术家可以通过与网格相关的名称来识别网格的形状。这些文件中的关系信息通常复杂度较低,因此 200 万条目上限绰绰有余。高复杂度通常会受到格式本身的限制,而且由于密集数据在许多(DCC)工具中性能不够好,因此在游戏行业中不太可能出现。然而,SceneAPI 非常重视处理速度,因为它的工作就是加载这些文件、处理它们并导出为各种引擎格式。SceneGraph的快速(非)分层迭代和快速查找有助于提供流畅的数据检索。
值得注意的功能
名称索引
SceneGraph中的节点都有一个名称,可用于以后定位。名称不一定是唯一的,但直系同胞的名称不能相同。当添加一个新节点时,它的全名将由它的父节点列表组成,从根节点开始,中间用点分隔。例如,一个名为 “Child ”的节点,其父节点名为 “Parent”,则其全名为 “Parent.Child”。存储的名称对象通过调用 GetPath 返回完整路径,而通过 GetName 只可返回名称部分。
端点
节点可以标记为 “终点”。端点节点不接受子节点,并在尝试时抛出断言。例如,“场景 ”流水线会将节点标记为属性。这样就可以区分网格变换和群变换,比如它们都有相同的数据,但一个是属性,另一个不是。这也使得只遍历节点的属性而跳过形成新组的子节点变得更容易。端点的具体含义取决于 SceneGraph 的使用方式,但它始终保证端点节点不会有任何子节点。
分层检索和平面检索
虽然 SceneGraph 的核心功能是提供节点的层次信息,但并非总是需要这些信息。有时需要的只是一个名称列表或某一类型的所有对象列表。例如,如果编辑器中的工具需要显示场景中所有骨骼的下拉列表,那么只需要名称和内容,以平面列表的形式遍历它们会更有效率,但当选定的骨骼被导出时,将需要层次信息来查找该骨骼的子节点和属性。SceneGraph为这两种情况提供了最佳支持,可根据需要使用一种或几种方法(稍后将详细介绍)。
Note:注意:虽然在某些情况下使用名称来查找父代很有吸引力,但这样做的成本比分层查找要高,而且不能保证将来一定有效。
保证根节点
SceneGraph保证至少有一个节点。默认情况下,根节点是一个无名节点。这一保证避免了处理无节点边缘情况的额外复杂性。这不仅有助于减少 SceneGraph 的 API,而且由于不需要任何测试来处理无条目情况,因此更易于使用。不过,如果不能选择空白根节点,则必须注意这一点。根节点的行为方式与其他节点相同,因此可以为其分配数据和同级节点。
内部布局
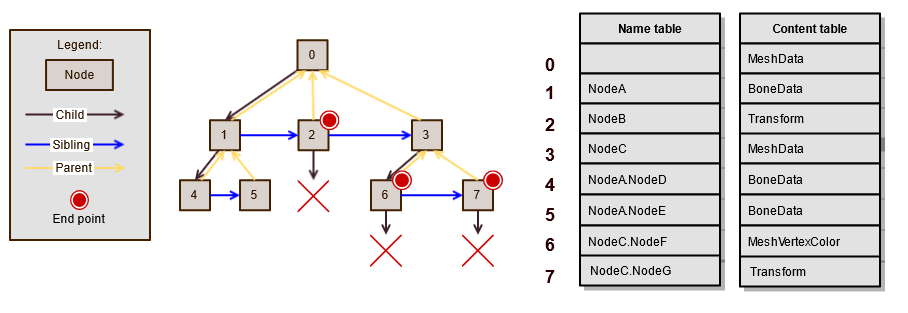
SceneGraph使用父节点-子节点-同级节点的方式来存储层次结构,而不是更常见的父节点-子节点存储方式。在这种方法中,父节点没有一个大小可变的数组来存储所有子节点,相反,单个节点有一个链接指向它的父节点、子节点和第一个同级节点。在这种情况下,同级节点是指处于同一层级并共享一个共同父节点的节点。同胞节点是父子树中的子节点,概念上与父节点的子节点相同。父-子-同胞方法保证了所有节点的固定大小,并有助于大幅减少添加新节点时所需的内存分配数量。在父子树中,所有节点都会单独分配内存来存放子节点,通常会多分配一些内存,以避免过于频繁地调整大小(矢量常用于这种情况),这导致每个节点在获得至少一个子节点后,就会立即分配内存。相比之下,父子树的节点大小固定,因此无需分配额外的内存。因此,单个节点数组就足够了,只有在需要调整数组大小以增加节点时,才需要分配内存。由于节点都存储在同一个数组中,因此它们也具有更好的内存定位性,而在最坏的情况下,父子树的单个子数组可能会非常分散。这样做的缺点是,在传统的父子树方法中,同胞兄弟姐妹不会在内存中靠得很近,这可能会导致在遍历图时在内存中发生多次跳转。不过,当 SceneGraph 与场景文件一起使用时,加载后的层次结构通常不会改变,从而在很大程度上避免了这个问题。
通过将父代、子代和同胞索引打包成 64 位的分层信息,避免了父代-子代-同胞方法的常见内存开销,但代价是将可用索引的数量限制在 200 万左右。为了进一步减少内存,我们避免了存储与节点相关的名称和内容指针,而是将 32 位索引存储到名称表和内容表中。
查询和导航
根据制作产品资产所需的自定义逻辑,有几种方法可以遍历SceneGraph。
基于索引的遍历
使用 SceneGraph 的最直接方法是使用基于索引的 API,该 API 以查询索引和使用索引获取节点信息为基础。获取索引可以通过 “Find(查找)”按名称搜索索引,或简单地调用 “GetRoot(获取根索引)”获取根索引并沿层次向下查找。有关节点的信息可通过几个基于索引的函数获取,如 “GetNodeName”、“HasNodeContent ”或 “IsNodeEndPoint”。通过调用 “GetNodeParent”(获取节点父节点)、“GetNodeChild”(获取节点子节点)或 “GetNodeSibling”(获取节点同级节点),可以导航到层次结构中的下一个节点。请务必通过调用 “IsValid() ”检查返回的索引是否有效,以确定是否已到达链的末端。
基于索引的好处是简单明了,易于访问。它也是最完整的 api,因为迭代器方法有其局限性,例如迭代器方法不允许添加新节点。在某些情况下,迭代器方法也会更快,最明显的是使用基于索引的方法按名称查找条目会快很多。
但缺点是,对于更广泛的使用,特别是在浏览整个树时,需要编写更多的模板代码,而迭代器提供的是开箱即用的代码。基于索引的方法目前也只支持分层导航,不允许对数据进行平面迭代。
索引示例:
// Print all attributes the crate mesh has.
NodeIndex current = sceneGraph.Find("CrateMesh");
if (current.IsValid())
{
current = sceneGraph.GetNodeChild(current);
}
while (current.IsValid())
{
if (sceneGraph.IsNodeEndPoint(current))
{
AZ_TracePrintf("Attribute: %s\n", sceneGraph.GetNodeName(current).c_str());
}
current = sceneGraph.GetNodeSibling(current);
}
基于迭代器的遍历
除了基于索引的访问外,SceneGraph的内容还可以通过迭代器进行访问,迭代器的行为类似于 AZStd::vector 或 AZStd::unordered_map 等常见容器的迭代器。为了减少需要处理的函数数量,begin 和 end 迭代器被合并为一个 “视图”。除了减少函数数量外,视图还允许使用范围 for 循环,而无需额外的封装类。为了方便起见,作为 SceneGraph 一部分的所有迭代器都以 Make<iterator>View 的形式提供了实用功能,以便轻松构建视图。
非分层
虽然 SceneGraph 的基本原理是以分层方式存储内容,但只需要简单访问值的情况并不少见。在这种情况下,SceneGraph 允许以平面方式访问:
- 存储内容(GetContentStorage)
- 存储的名称(GetNameStorage)
- 层次信息(GetHierarchyStorage)
这些列表可以单独迭代,但如果需要多个值(如名称和内容),可以考虑使用 PairIterator 将它们组合起来。对于过滤,可以使用 FilterIterator,它可以使用任何函数来应用过滤,但为了方便起见,使用 TypeFilter 结构通常更容易。使用 ExactTypeFilter 可以过滤精确类型的类,使用 DerivedTypeFilter 则可以搜索从所提供的 IManifestObject 或 IGraphObject 派生的任何类。在处理 SceneManifest 时,也可以使用这两个迭代器和实用结构体。
非层次迭代器:
// Print all the names used in the graph
NameStorageConstData names = sceneGraph.GetNameStorage();
for( const std::string& name : names )
{
AZ_TracePrintf( "Graph elements: %s\n", name.c_str());
}
// Collect all selected meshes.
auto content = sceneGraph.GetContentStorage();
auto view = SceneContainers::Views::MakePairView(names, content);
AZStd::vector<AZStd::shared_ptr<SceneDataTypes::IGraphObject>> selectedMeshes;
for (auto& iterator : view)
{
if (IsMeshSelected(iterator.first.c_str()))
{
selectedMeshes.push_back(iterator.second);
}
}
基于层次的遍历
SceneGraph 通过树形迭代器提供分层迭代:
- SceneGraphUpwardsIterator 来从节点导航到根节点。
- SceneGraphDownwardsIterator 以广度优先或深度优先的方式从给定节点向下移动。
- SceneGraphChildIterator 来列出节点的所有直接子节点。
使用这些迭代器可以大大简化对图形进行迭代时通常需要的管理,同时以平面列表的形式显示迭代结果。这些迭代器采用节点索引或分层迭代器(由 GetHierarchyStorage 返回)以及表示返回值的迭代器(通常是名称、内容或两者的组合)。如果分层迭代器或节点索引不是从根开始,但给定的迭代器确实从根开始,则可以通过将 “rootIterator ”布尔值设置为 true 自动将迭代器移动到正确的位置。
分层向上迭代示例:
auto content = sceneGraph.GetContentStorage();
auto view = SceneViews::MakeSceneGraphUpwardsView(graph, nodeIterator, content.cbegin(), true);
for (const auto& node : view)
{
if (node)
{
const SceneDataTypes::ITransform* nodeTransform = azrtti_cast<const SceneDataTypes::ITransform*>(node.get());
if (nodeTransform)
{
transform = nodeTransform->GetMatrix() * transform;
}
}
}
分层向下迭代示例:
auto names = sceneGraph.GetNameStorage();
auto content = sceneGraph.GetContentStorage();
auto pairView = MakePairView(names, content);
auto view = MakeSceneGraphDownwardsView<BreadthFirst>(sceneGraph, sceneGraph.GetRoot(), pairView.cbegin(), true);
for (const auto& iterator = view.begin(); iterator != view.end(); ++iterator )
{
uint64_t parentIndex = itertator.GetHierarchyIterator()->m_parentIndex;
bool isMesh = iterator.second->RTTI_IsTypeOf(IMeshData::TYPEINFO_Uuid());
QIcon& icon = isMesh ? GetMeshIcon() : GetDefaultIcon();
uiTree[parentIndex].AddChild(iterator->first.c_str(), icon);
}
// Check if a node has an animation data attribute.
auto content = sceneGraph.GetContentStorage();
auto view = MakeSceneGraphChildView<AcceptEndPointsOnly>(graph, nodeIterator, content.begin(), true);
auto result = AZStd::find_if(view.begin(), view.end(), DerivedTypeFilter<IAnimationData>());
return result != childView.end();
在索引和迭代器之间转换
有时迭代器会完成部分工作,但最后的步骤需要索引,有时情况恰恰相反。针对这些情况,SceneGraph提供了一些转换函数,可将任何基本迭代器转换为节点索引(ConvertToNodeIndex)或将节点索引转换为层次结构迭代器(ConvertToHierarchyIterator)。请注意,为了在循环中使用这些迭代器,迭代器本身是必需的,这意味着它不能与范围 for 循环结合使用。
NodeHeader 和 NodeIndex
与使用普通的 64 位和 32 位整数相比,分层信息和索引分别存储在 NodeHeader 和 NodeIndex 中。尽管这些都是对象,但建议以值传递,因为这比以引用传递更快。
节点层次结构以 64 位存储,其中 21 位用于父节点、子节点和同级节点的索引,总共 63 位。最后一位用于指示节点是否为端点。节点头以比特字段的形式提供这些信息,并有一些用于基本状态查询的实用功能。
NodeIndex 用于通过限制某些功能(如各种比较)来更具体地编码图形索引的原理。此外,还特意降低了如何创建新 NodeIndex 的清晰度,从而促进了 SceneGraph 的使用,并避免了一些常见的无效索引问题。